To better understand PySparks API and data structures, recall the Hello World program mentioned previously: The entry-point of any PySpark program is a SparkContext object. This means filter() doesnt require that your computer have enough memory to hold all the items in the iterable at once. Do you observe increased relevance of Related Questions with our Machine why exactly should we avoid using for loops in PySpark? Should Philippians 2:6 say "in the form of God" or "in the form of a god"? No spam ever. rev2023.4.5.43379. Sets are very similar to lists except they do not have any ordering and cannot contain duplicate values.
Thanks for contributing an answer to Stack Overflow! However, all the other components such as machine learning, SQL, and so on are all available to Python projects via PySpark too.
If we see the result above we can see that the col will be called one after other sequentially despite the fact we have more executor memory and cores. Should Philippians 2:6 say "in the form of God" or "in the form of a god"? You can read Sparks cluster mode overview for more details. All of the complicated communication and synchronization between threads, processes, and even different CPUs is handled by Spark. You can work around the physical memory and CPU restrictions of a single workstation by running on multiple systems at once. take() is important for debugging because inspecting your entire dataset on a single machine may not be possible. To learn more, see our tips on writing great answers. Prove HAKMEM Item 23: connection between arithmetic operations and bitwise operations on integers, How can I "number" polygons with the same field values with sequential letters.
Python allows the else keyword with for loop. Can be used for sum or counter. Take a look at Docker in Action Fitter, Happier, More Productive if you dont have Docker setup yet. The answer wont appear immediately after you click the cell. Making statements based on opinion; back them up with references or personal experience. pyspark.rdd.RDD.mapPartition method is lazily evaluated. The underlying graph is only activated when the final results are requested. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. I actually tried this out, and it does run the jobs in parallel in worker nodes surprisingly, not just the driver!  Even better, the amazing developers behind Jupyter have done all the heavy lifting for you. Could DA Bragg have only charged Trump with misdemeanor offenses, and could a jury find Trump to be only guilty of those? Asking for help, clarification, or responding to other answers. As in any good programming tutorial, youll want to get started with a Hello World example. So my question is: how should I augment the above code to be run on 500 parallel nodes on Amazon Servers using the PySpark framework? How are you going to put your newfound skills to use? Efficiently handling datasets of gigabytes and more is well within the reach of any Python developer, whether youre a data scientist, a web developer, or anything in between. When a task is distributed in Spark, it means that the data being operated on is split across different nodes in the cluster, and that the tasks are being performed concurrently. However, by default all of your code will run on the driver node. B-Movie identification: tunnel under the Pacific ocean. This post discusses three different ways of achieving parallelization in PySpark: Ill provide examples of each of these different approaches to achieving parallelism in PySpark, using the Boston housing data set as a sample data set. Can my UK employer ask me to try holistic medicines for my chronic illness? How do I iterate through two lists in parallel? Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA.
Even better, the amazing developers behind Jupyter have done all the heavy lifting for you. Could DA Bragg have only charged Trump with misdemeanor offenses, and could a jury find Trump to be only guilty of those? Asking for help, clarification, or responding to other answers. As in any good programming tutorial, youll want to get started with a Hello World example. So my question is: how should I augment the above code to be run on 500 parallel nodes on Amazon Servers using the PySpark framework? How are you going to put your newfound skills to use? Efficiently handling datasets of gigabytes and more is well within the reach of any Python developer, whether youre a data scientist, a web developer, or anything in between. When a task is distributed in Spark, it means that the data being operated on is split across different nodes in the cluster, and that the tasks are being performed concurrently. However, by default all of your code will run on the driver node. B-Movie identification: tunnel under the Pacific ocean. This post discusses three different ways of achieving parallelization in PySpark: Ill provide examples of each of these different approaches to achieving parallelism in PySpark, using the Boston housing data set as a sample data set. Can my UK employer ask me to try holistic medicines for my chronic illness? How do I iterate through two lists in parallel? Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA.
Another PySpark-specific way to run your programs is using the shell provided with PySpark itself. There are higher-level functions that take care of forcing an evaluation of the RDD values. to use something like the wonderful pymp. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. How to add a new column to an existing DataFrame? where symbolize takes a Row of symbol x day and returns a tuple (symbol, day). Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. It can be created in the following way: 1. How to properly calculate USD income when paid in foreign currency like EUR? 
Finally, the last of the functional trio in the Python standard library is reduce(). Spark timeout java.lang.RuntimeException: java.util.concurrent.TimeoutException: Timeout waiting for task while writing to HDFS.
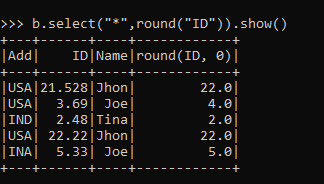
In my scenario, I exported multiple tables from SQLDB to a folder using a notebook and ran the requests in parallel. Finally, special_function isn't some simple thing like addition, so it can't really be used as the "reduce" part of vanilla map-reduce I think. The loop does run sequentially, but for each symbol the execution of: is done in parallel since markedData is a Spark DataFrame and it is distributed. Typically, youll run PySpark programs on a Hadoop cluster, but other cluster deployment options are supported. Spark itself runs job parallel but if you still want parallel execution in the code you can use simple python code for parallel processing to do it (this was tested on DataBricks Only link). Connect and share knowledge within a single location that is structured and easy to search. Usually to force an evaluation, you can a method that returns a value on the lazy RDD instance that is returned. -- But not across task. Provides broadcast variables & accumulators. Preserve paquet file names in PySpark. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. But on the other hand if we specified a threadpool of 3 we will have the same performance because we will have only 100 executors so at the same time only 2 tasks can run even though three tasks have been submitted from the driver to executor only 2 process will run and the third task will be picked by executor only upon completion of the two tasks. Can pymp be used in AWS? Py4J allows any Python program to talk to JVM-based code. A ParallelLoopState variable that you can use in your delegate's code to examine the state of the loop. First, youll see the more visual interface with a Jupyter notebook. Despite its popularity as just a scripting language, Python exposes several programming paradigms like array-oriented programming, object-oriented programming, asynchronous programming, and many others. With this feature, you can partition a Spark data frame into smaller data sets that are distributed and converted to Pandas objects, where your function is applied, and then the results are combined back into one large Spark data frame. The. Spark has a number of ways to import data: You can even read data directly from a Network File System, which is how the previous examples worked. In this guide, youll see several ways to run PySpark programs on your local machine. Please explain why/how the commas work in this sentence. How to run independent transformations in parallel using PySpark? In a Python context, think of PySpark has a way to handle parallel processing without the need for the threading or multiprocessing modules. Below is the PySpark equivalent: Dont worry about all the details yet. You can imagine using filter() to replace a common for loop pattern like the following: This code collects all the strings that have less than 8 characters. Spark uses Resilient Distributed Datasets (RDD) to perform parallel processing across a cluster or computer processors. Why can I not self-reflect on my own writing critically? Let us see the following steps in detail. How to change the order of DataFrame columns? Leave a comment below and let us know. They publish a Dockerfile that includes all the PySpark dependencies along with Jupyter. I will show comments Are there any sentencing guidelines for the crimes Trump is accused of? How to loop through each row of dataFrame in pyspark. Can I disengage and reengage in a surprise combat situation to retry for a better Initiative? How to convince the FAA to cancel family member's medical certificate? Essentially, Pandas UDFs enable data scientists to work with base Python libraries while getting the benefits of parallelization and distribution. Now that we have the data prepared in the Spark format, we can use MLlib to perform parallelized fitting and model prediction. You need to use that URL to connect to the Docker container running Jupyter in a web browser. The following code creates an iterator of 10,000 elements and then uses parallelize() to distribute that data into 2 partitions: parallelize() turns that iterator into a distributed set of numbers and gives you all the capability of Sparks infrastructure. rev2023.4.5.43379. The return value of compute_stuff (and hence, each entry of values) is also custom object. You simply cannot. Would spinning bush planes' tundra tires in flight be useful? The above statement prints theentire table on terminal. How to convince the FAA to cancel family member's medical certificate? One of the ways that you can achieve parallelism in Spark without using Spark data frames is by using the multiprocessing library. Notice that the end of the docker run command output mentions a local URL. In this guide, youll only learn about the core Spark components for processing Big Data. One of the ways that you can achieve parallelism in Spark without using Spark data frames is by using the multiprocessing library. Please explain why/how the commas work in this sentence. Youve likely seen lambda functions when using the built-in sorted() function: The key parameter to sorted is called for each item in the iterable.
I have seven steps to conclude a dualist reality. Split a CSV file based on second column value. from pyspark.sql import SparkSession spark = SparkSession.builder.master ('yarn').appName ('myAppName').getOrCreate () spark.conf.set ("mapreduce.fileoutputcommitter.marksuccessfuljobs", "false") data = [a,b,c] for i in data: On Images of God the Father According to Catholicism? Here's an example of the type of thing I'd like to parallelize: X = np.random.normal (size= (10, 3)) F = np.zeros ( (10, )) for i in range (10): F [i] = my_function (X [i,:]) where my_function takes an ndarray of size (1,3) and returns a scalar. Here's a parallel loop on pyspark using azure databricks. Why would I want to hit myself with a Face Flask? Do you observe increased relevance of Related Questions with our Machine Pairwise Operations between Rows of Spark Dataframe (Pyspark), How to update / delete in snowflake from the AWS Glue script, Finding Continuous Month-to-Month Enrollment Periods in PySpark. say the sagemaker Jupiter notebook? In the Spark ecosystem, RDD is the basic data structure that is used in PySpark, it is an immutable collection of objects that is the basic point for a Creating a SparkContext can be more involved when youre using a cluster. Its possible to have parallelism without distribution in Spark, which means that the driver node may be performing all of the work. import socket from multiprocessing.pool import ThreadPool pool = ThreadPool(10) def getsock(i): s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) s.connect(("8.8.8.8", 80)) return s.getsockname()[0] list(pool.map(getsock,range(10))) This always gives the same IP address. However, for now, think of the program as a Python program that uses the PySpark library. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide.
No spam. The Docker container youve been using does not have PySpark enabled for the standard Python environment. How to convince the FAA to cancel family member's medical certificate? To learn more, see our tips on writing great answers. The map function takes a lambda expression and array of values as input, and invokes the lambda expression for each of the values in the array. Each iteration of the inner loop takes 30 seconds, but they are completely independent. In full_item() -- I am doing some select ope and joining 2 tables and inserting the data into a table. Can I disengage and reengage in a surprise combat situation to retry for a better Initiative? Before showing off parallel processing in Spark, lets start with a single node example in base Python. The new iterable that map() returns will always have the same number of elements as the original iterable, which was not the case with filter(): map() automatically calls the lambda function on all the items, effectively replacing a for loop like the following: The for loop has the same result as the map() example, which collects all items in their upper-case form. How many sigops are in the invalid block 783426? To learn more, see our tips on writing great answers. Create a Pandas Dataframe by appending one row at a time. 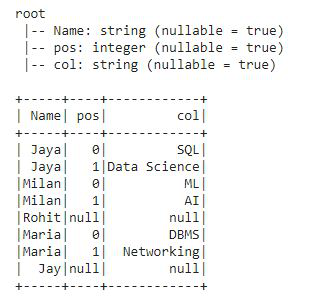 We now have a task that wed like to parallelize. Improving the copy in the close modal and post notices - 2023 edition. rev2023.4.5.43379. Example output is below: Theres multiple ways of achieving parallelism when using PySpark for data science. this is parallel execution in the code not actuall parallel execution.
We now have a task that wed like to parallelize. Improving the copy in the close modal and post notices - 2023 edition. rev2023.4.5.43379. Example output is below: Theres multiple ways of achieving parallelism when using PySpark for data science. this is parallel execution in the code not actuall parallel execution.
 You can do this manually, as shown in the next two sections, or use the CrossValidator class that performs this operation natively in Spark. Theres no shortage of ways to get access to all your data, whether youre using a hosted solution like Databricks or your own cluster of machines. Post-apoc YA novel with a focus on pre-war totems, B-Movie identification: tunnel under the Pacific ocean. Can you travel around the world by ferries with a car? There is no call to list() here because reduce() already returns a single item. Not the answer you're looking for? Once all of the threads complete, the output displays the hyperparameter value (n_estimators) and the R-squared result for each thread. This object allows you to connect to a Spark cluster and create RDDs. Spark Streaming processing from multiple rabbitmq queue in parallel, How to use the same spark context in a loop in Pyspark, Spark Hive reporting java.lang.NoSuchMethodError: org.apache.hadoop.hive.metastore.api.Table.setTableName(Ljava/lang/String;)V, Validate the row data in one pyspark Dataframe matched in another Dataframe, How to use Scala UDF accepting Map[String, String] in PySpark. Manually raising (throwing) an exception in Python, Iterating over dictionaries using 'for' loops. It might not be the best practice, but you can simply target a specific column using collect(), export it as a list of Rows, and loop through the list. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. At its core, Spark is a generic engine for processing large amounts of data. My experiment setup was using 200 executors, and running 2 jobs in series would take 20 mins, and running them in ThreadPool takes 10 mins in total.
You can do this manually, as shown in the next two sections, or use the CrossValidator class that performs this operation natively in Spark. Theres no shortage of ways to get access to all your data, whether youre using a hosted solution like Databricks or your own cluster of machines. Post-apoc YA novel with a focus on pre-war totems, B-Movie identification: tunnel under the Pacific ocean. Can you travel around the world by ferries with a car? There is no call to list() here because reduce() already returns a single item. Not the answer you're looking for? Once all of the threads complete, the output displays the hyperparameter value (n_estimators) and the R-squared result for each thread. This object allows you to connect to a Spark cluster and create RDDs. Spark Streaming processing from multiple rabbitmq queue in parallel, How to use the same spark context in a loop in Pyspark, Spark Hive reporting java.lang.NoSuchMethodError: org.apache.hadoop.hive.metastore.api.Table.setTableName(Ljava/lang/String;)V, Validate the row data in one pyspark Dataframe matched in another Dataframe, How to use Scala UDF accepting Map[String, String] in PySpark. Manually raising (throwing) an exception in Python, Iterating over dictionaries using 'for' loops. It might not be the best practice, but you can simply target a specific column using collect(), export it as a list of Rows, and loop through the list. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. At its core, Spark is a generic engine for processing large amounts of data. My experiment setup was using 200 executors, and running 2 jobs in series would take 20 mins, and running them in ThreadPool takes 10 mins in total.
Do you observe increased relevance of Related Questions with our Machine How do you run multiple programs in parallel from a bash script?  ', 'is', 'programming'], ['awesome! Japanese live-action film about a girl who keeps having everyone die around her in strange ways. Seal on forehead according to Revelation 9:4. Step 1- Install foreach package I created a spark dataframe with the list of files and folders to loop through, passed it to a pandas UDF with specified number of partitions (essentially cores to parallelize over).
', 'is', 'programming'], ['awesome! Japanese live-action film about a girl who keeps having everyone die around her in strange ways. Seal on forehead according to Revelation 9:4. Step 1- Install foreach package I created a spark dataframe with the list of files and folders to loop through, passed it to a pandas UDF with specified number of partitions (essentially cores to parallelize over).
Related Tutorial Categories: The statements in the else block will execute after completing all the iterations of the loop. How do I iterate through two lists in parallel? Seal on forehead according to Revelation 9:4. .. Another less obvious benefit of filter() is that it returns an iterable. For example, we have a parquet file with 2000 stock symbols' closing price in the past 3 years, and we want to calculate the 5-day moving average for each symbol. However, reduce() doesnt return a new iterable. Dealing with unknowledgeable check-in staff. If not, Hadoop publishes a guide to help you. Which of these steps are considered controversial/wrong? I used the Databricks community edition to author this notebook and previously wrote about using this environment in my PySpark introduction post. Again, to start the container, you can run the following command: Once you have the Docker container running, you need to connect to it via the shell instead of a Jupyter notebook. 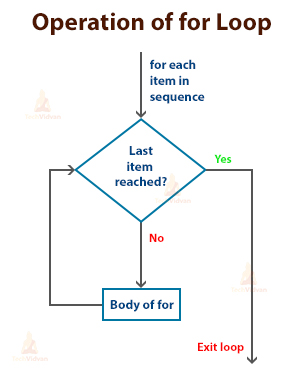 The cluster I have access to has 128 GB Memory, 32 cores. To interact with PySpark, you create specialized data structures called Resilient Distributed Datasets (RDDs). Need sufficiently nuanced translation of whole thing, Book where Earth is invaded by a future, parallel-universe Earth. The snippet below shows how to perform this task for the housing data set. I am using Azure Databricks to analyze some data. We take your privacy seriously. For SparkR, use setLogLevel(newLevel). Spark is written in Scala and runs on the JVM. What is the alternative to the "for" loop in the Pyspark code? This is useful for testing and learning, but youll quickly want to take your new programs and run them on a cluster to truly process Big Data.
The cluster I have access to has 128 GB Memory, 32 cores. To interact with PySpark, you create specialized data structures called Resilient Distributed Datasets (RDDs). Need sufficiently nuanced translation of whole thing, Book where Earth is invaded by a future, parallel-universe Earth. The snippet below shows how to perform this task for the housing data set. I am using Azure Databricks to analyze some data. We take your privacy seriously. For SparkR, use setLogLevel(newLevel). Spark is written in Scala and runs on the JVM. What is the alternative to the "for" loop in the Pyspark code? This is useful for testing and learning, but youll quickly want to take your new programs and run them on a cluster to truly process Big Data.
Spark is a distributed parallel computation framework but still there are some functions which can be parallelized with python multi-processing Module. Connect and share knowledge within a single location that is structured and easy to search. Azure Databricks: Python parallel for loop. Note: Replace 4d5ab7a93902 with the CONTAINER ID used on your machine. The command-line interface offers a variety of ways to submit PySpark programs including the PySpark shell and the spark-submit command. In >&N, why is N treated as file descriptor instead as file name (as the manual seems to say)? rev2023.4.5.43379. For a more detailed understanding check this out. Making statements based on opinion; back them up with references or personal experience.
Can you select, or provide feedback to improve?
Holy Spirit Burning In Chest, Diy Body Blade, Articles P